In the first part of this article, I described the somewhat circuitous path that led me to build this application: the language frustrations, the ecological considerations, the appeal of running something entirely local. This second part is less personal and more technical: the architectural choices, the problems I ran into, and how I solved them.
Under the hood
The application is built in two distinct parts: a Node.js/Express backend and a React/Vite frontend, communicating through a REST API. The choice of Node.js/Express was pragmatic. I considered Next.js briefly, then set it aside. I know Express well enough to move quickly, and moving quickly was the priority. The backend acts as an intermediary: it receives the user's input, queries Ollama, and returns the response to the frontend. Nothing leaves the machine at any point in this process.
Ollama runs locally on the Mac Mini and serves the model through a straightforward HTTP interface. One architectural decision I made early on was to abstract the LLM layer behind a provider factory. In practice, this means that swapping to a different model provider (local or remote) only requires changing an environment variable. The rest of the application is unaffected. This felt like the kind of thing that would cost very little effort to do correctly upfront and a great deal of effort to retrofit later.
The model running inside Ollama is llama3:8b. It is lightweight enough to run on 16GB of RAM without a dedicated GPU. I should be honest, though: it was not my first choice. I tested Mistral first and found it incapable of producing coherent grammatical analysis or reliable translation for Icelandic.llama3:8b was chosen by elimination as much as by merit.
The streaming problem
The first working version of the app displayed the model's response all at once, after a wait of one to two minutes. Technically functional, barely usable. Every query felt like submitting a form and then staring at the wall. The obvious solution was streaming: receiving and displaying tokens as they are generated rather than waiting for the full response.
I implemented this using Server-Sent Events. WebSockets would have worked too, but the communication here is strictly one-way: the model talks, the frontend listens. SSE is simpler and entirely sufficient. In practice, Ollama streams the response as a sequence of line-by-line JSON fragments; the backend reads them chunk by chunk and forwards them to the frontend over an open HTTP connection. The first tokens now appear in roughly half a second. A full response takes between ten and twenty seconds. For a personal tool, that is perfectly acceptable.
The harder problem
Streaming was the straightforward part. The harder problem was making the analysis reliable enough to be useful.
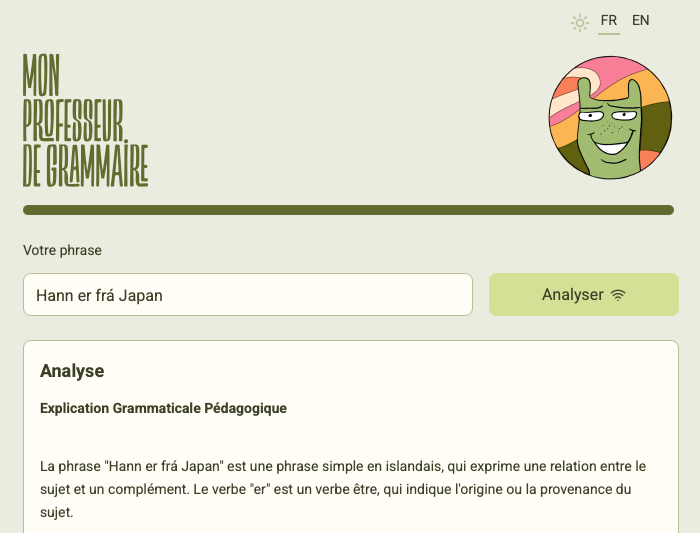
The first version of the pipeline asked the model to translate the Icelandic sentence and then analyse its grammar in a single pass. This produced a specific kind of failure: the model would base its grammatical analysis on the English translation it had just generated, rather than on the original Icelandic. The results were sometimes plausible-sounding and entirely wrong. An Icelandic verb would be parsed according to English grammatical logic. A case ending would be explained in terms that made sense in English and nonsense in Icelandic.
The solution was to break the process into two strictly separate phases, each with its own prompt and its own model parameters. The first phase is silent: the user never sees it. It performs a word-by-word morphological tokenisation of the sentence, using a strict output format. No translation is requested. To prevent the model from adding preamble or reformulating the task in its own words, I use a prefill trick: the prompt ends with the beginning of the expected answer, forcing the model to continue from that point rather than starting fresh. Once tokenisation is complete, a verification pass - run at deterministic temperature - evaluates the output and responds either OK or ERROR: <description>. If an error is flagged, a targeted correction prompt addresses only the identified issue.
The second phase takes the verified token list as its input. The model no longer sees the raw Icelandic sentence. It produces a syntactic and pedagogical analysis built on tokens that have already been validated. The two phases do not share context. This part of the build took the most time, not because the implementation was technically complex, but because getting the prompts right required many iterations, and each iteration took a few minutes to evaluate.
What works and what doesn't
The anti-hallucination pipeline handles most edge cases well. Where the app still struggles is translation. llama3:8b is not reliable on Icelandic in this respect. A simple sentence like Ég talar ensku - "I speak English" - is almost consistently rendered as "I speak Swedish". There is something almost poetic about a grammar teacher that confidently names the wrong language. I have not fixed this.
One possibility I am considering is running a dedicated translation model alongside the main one - NLLB, for instance, which was specifically trained for low-resource languages. Whether this is worth the overhead of running two models locally is an open question. It may well be overkill for a tool I use alone, on my sofa, to understand adjective endings.
The frontend, for its part, was designed with some care: light and dark themes, a bilingual interface switchable at runtime, a layout that makes the app feel like something worth opening.
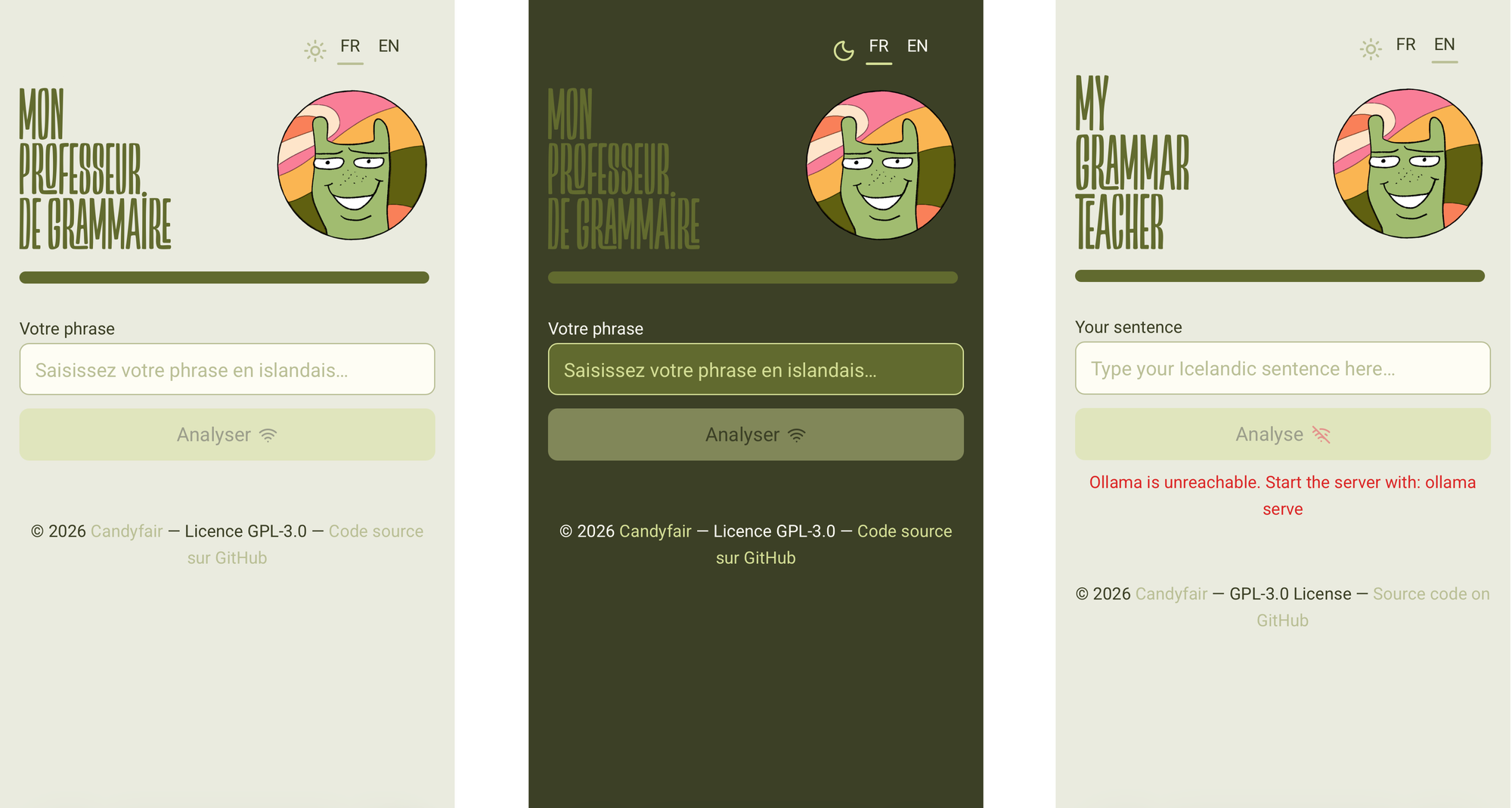
Investing time in the interface of a personal tool is a choice worth acknowledging. A well-designed environment changes your daily relationship with the tool, even when no one else will see it. There is a version of this reasoning that sounds like rationalisation, and I am aware of that. But the line between "good enough for personal use" and "worth doing properly" is, in my experience, a design question as much as a technical one. I tend to land on the side of doing it properly, and I have not yet found a reason to regret that habit.